Improving Platform Reliability with Qpoint


I joined Qpoint to tackle the persistent challenges that platform engineering teams face building distributed applications and PaaS offerings for internal consumption, the subject of which I am intimately familiar with from roles at DigitalOcean and elsewhere. Platform teams generally use a variety of services to compose their systems. For example, a public PaaS may include mechanisms for storing files in a web-accessible manner, operating clusters, and managing domains, DNS, Docker registries, load balancers, and more. These services are not unique to a PaaS as most medium-scale systems employ many of the same services.
In most cases, these systems are composed from a combination of self-hosted and third-party services. The teams that build and operate these platforms can experience a wide variety of issues within and outside of their control. Finding the root cause of an issue is important, but knowing that it exists at all is even more critical.
How do platform teams typically manage third-party API dependencies?
Most teams employ a reactive approach, basically doing nothing until an outage in a dependency causes a cascading failure in the system. When a failure does occur, they spend time frantically trying to find the issue, eventually identifying it with bittersweet relief that the root cause is not in one of their in-house services.
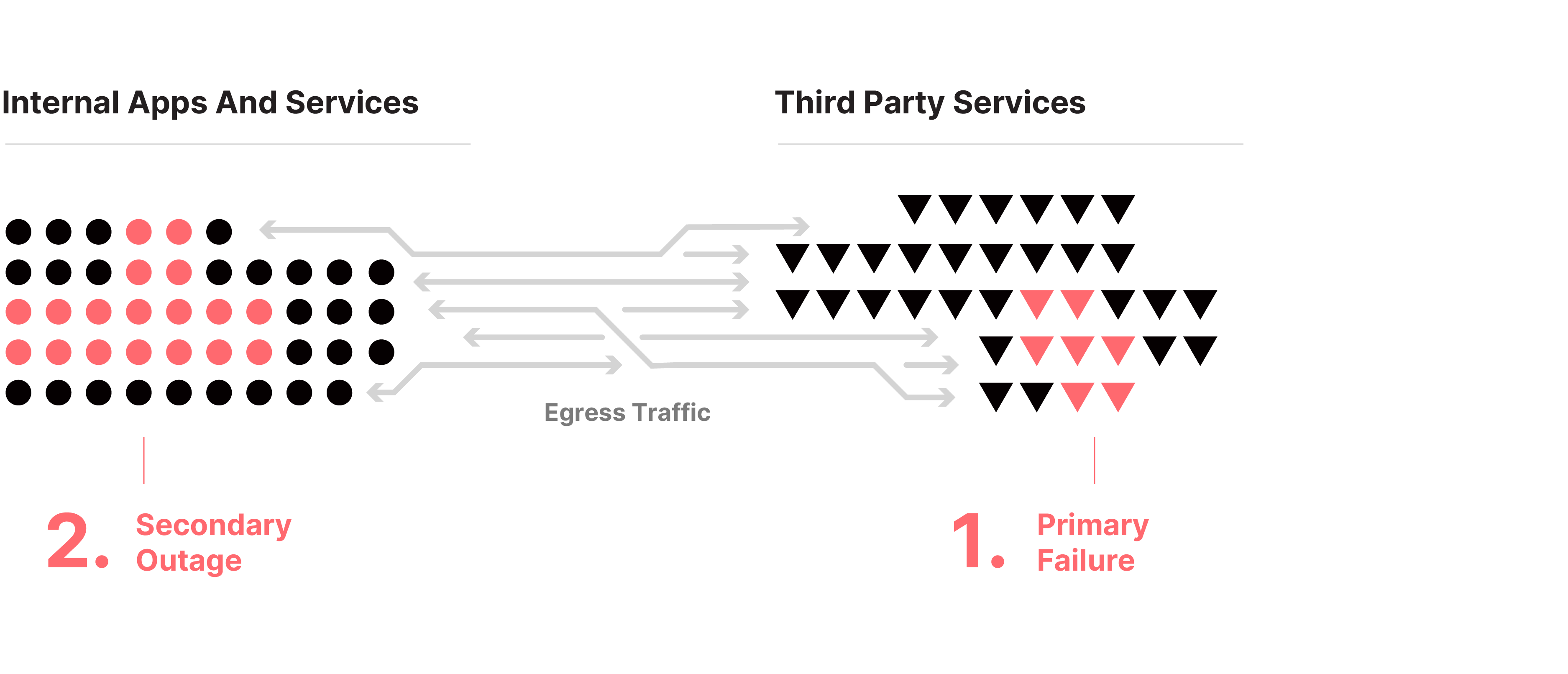
This approach often results in significant downtime and disruption, as teams scramble to troubleshoot and resolve the issue. The lack of proactive monitoring and management means that recurring issues with third-party APIs are not addressed systematically, leading to a cycle of repeated failures and reactive firefighting.
How are issues and outages handled?
Over time, dependencies will have outages. A keen engineer may make a list of status pages and check those first, perhaps going a step further by subscribing to their Slack channels or RSS feeds.
Ultimately, there will be problematic dependencies that have recurring issues. This is where things start to require significant investment of time and effort. Something needs to be done, and this often starts with building monitoring and alerting right into your product - followed by adding in circuit breakers and augmenting business logic to manage flaky services.
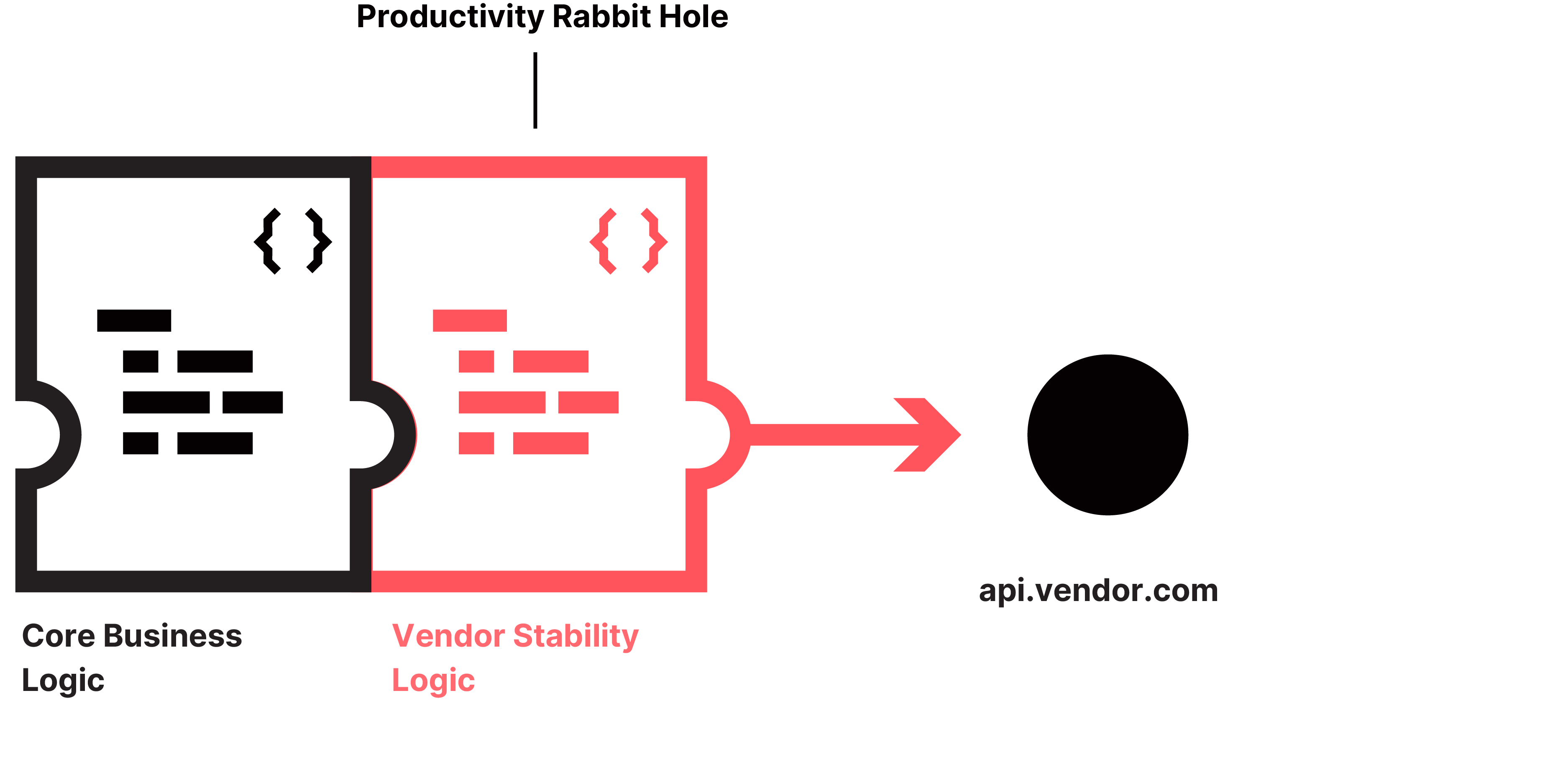
This leads to a productivity rabbit hole, especially in larger projects where product and operations teams are separate. This rabbit hole never truly goes away because the safeguards added need to be maintained, updated, and understood by product developers going forward. It introduces a permanent level of technical debt that the organization must always pay interest on.
How Qpoint Helps
Observability
Qpoint's egress observability product, Qtap, can exponentially lower the mean-time-to-resolution for issues and outages while significantly reducing technical debt. It enables platform teams to immediately answer critical questions, such as:
- What services are being used?
- How much are they being used?
- When failures and degradations occur, where are they happening?
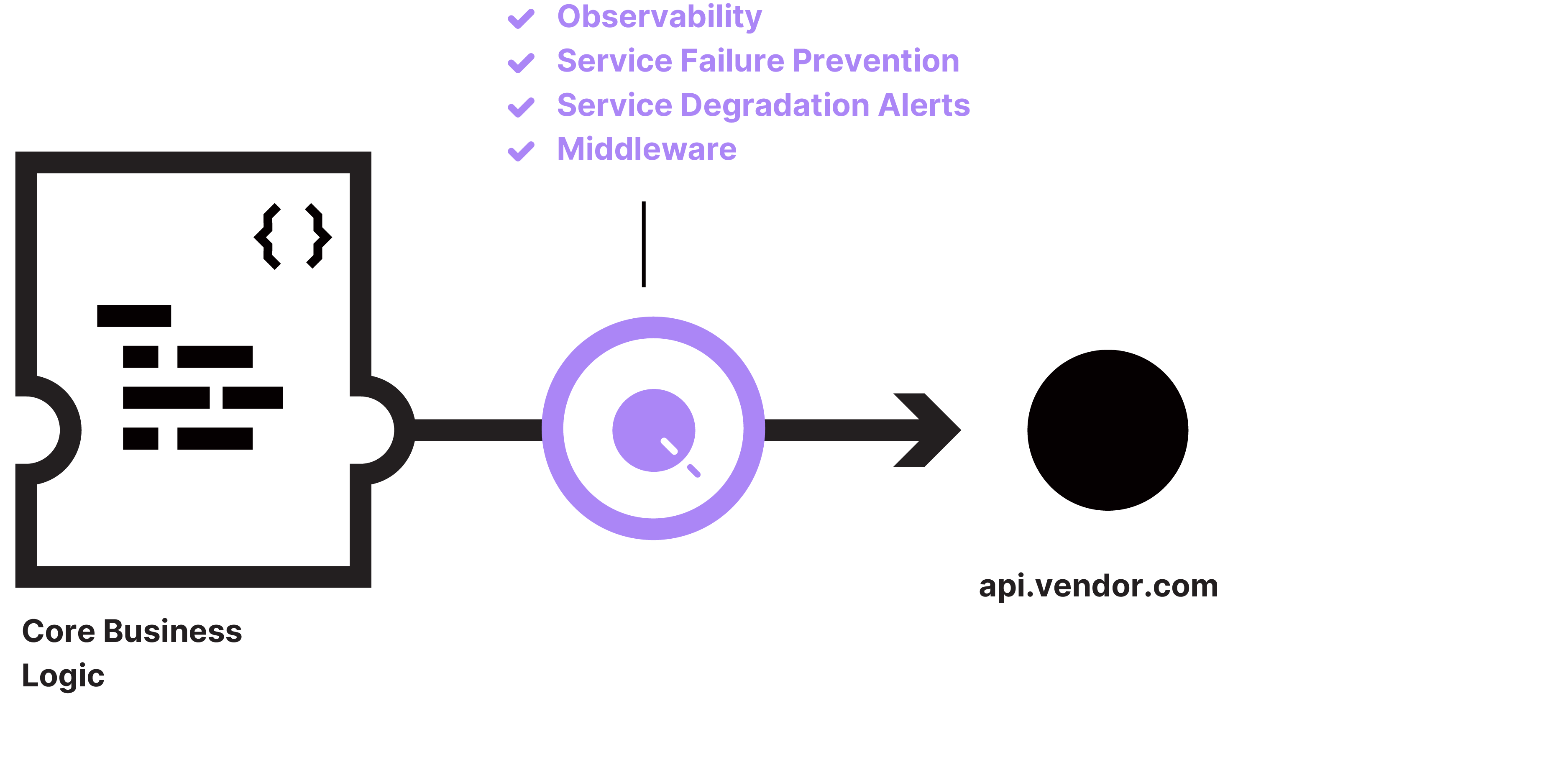
Middleware
Qpoint products are powered by a next generation middleware framework that allows an operator to implement fine-grained controls over egress traffic using customizable WASM-based functions. Platform teams can use the Qpoint middleware catalog to employ mitigation strategies across their services that fit the organization’s culture and outage mitigation protocol. Custom middleware functions can be written and deployed to fill in the gaps if a desired strategy is not covered by the catalog.
Conclusion
Addressing the complexities of modern systems requires a proactive and strategic approach. By leveraging Qpoint, organizations can significantly reduce the mean-time-to-resolution for service issues and eliminate the technical debt associated with ad hoc safeguards. This ensures a more resilient infrastructure, enabling operations teams to focus on innovation rather than firefighting. Ultimately, integrating comprehensive monitoring, alerting, and mitigation strategies centered around the egress traffic from your production applications will not only enhance system reliability but also further the organization’s long-term goals of efficiency and stability.
Are you interested in unparalleled visibility into and control over the egress traffic from your core applications to improve the reliability of your platform?
Explore how Qpoint can enable your team to enhance observability, increase operational resilience, and lock down egress traffic with a zero trust approach.